Exploration
Active
Inference
Exploring a New Frontier in Machine Learning
Instructions: Tap to move the agent around LineWorld.
Learning is What?! Fundamental.
What if a machine could learn not just from data we hand it, but from data it goes out and gathers on its own? That's the idea behind Active Inference — and it reframes what "learning" even means.
Dr. Karl Friston, one of the most cited neuroscientists alive, developed this framework. Active Inference is built on the principle of free energy minimization — a fancy way of saying reducing surprise. The claim is that learning is just a system's attempt to make its world more predictable.
Learning is just a stochastic system in a stochastic world minimizing its surprise (aka its free energy). Just like a ball rolls down a hill to minimize energy, a learning system rolls down a hill to minimize surprise.
What do you, as an intelligent learning machine, do when you're surprised? You learn! You assess your actions, interpret the feedback from your environment, and refine your internal model of the world. You learn.
The Brain's Algorithm
I got into Active Inference after reading a Wired profile of Friston that made the free energy principle feel genuinely urgent, which then led me to the MIT Press textbook where the math finally clicked. I was hooked. Even simple examples felt like something out of science fiction. What's wild is how broadly it applies — even to things you wouldn't normally consider intelligent. If something can be viewed as taking actions on its environment, Active Inference might have something to say about it.
An "agent" is really loosely defined in Active Inference. A single cell can be seen as an agent, as can a whole organism, or even a group of organisms. The only real delineator is whether or not the system can be viewed as having a reasonably separate internal "state" from its environment (in mathematical terms — where there is a Markov blanket).
Distilled down, an Active Inference agent runs a loop: Observe, Infer, and Act — where inference itself involves estimating how surprising each possible action would be. Each step uses Bayesian inference to update beliefs, and the whole cycle drives toward less surprise. The agent starts with a generative model of its world — how observations relate to states, how actions change states — but it doesn't need pre-training on task-specific data. It learns by acting.
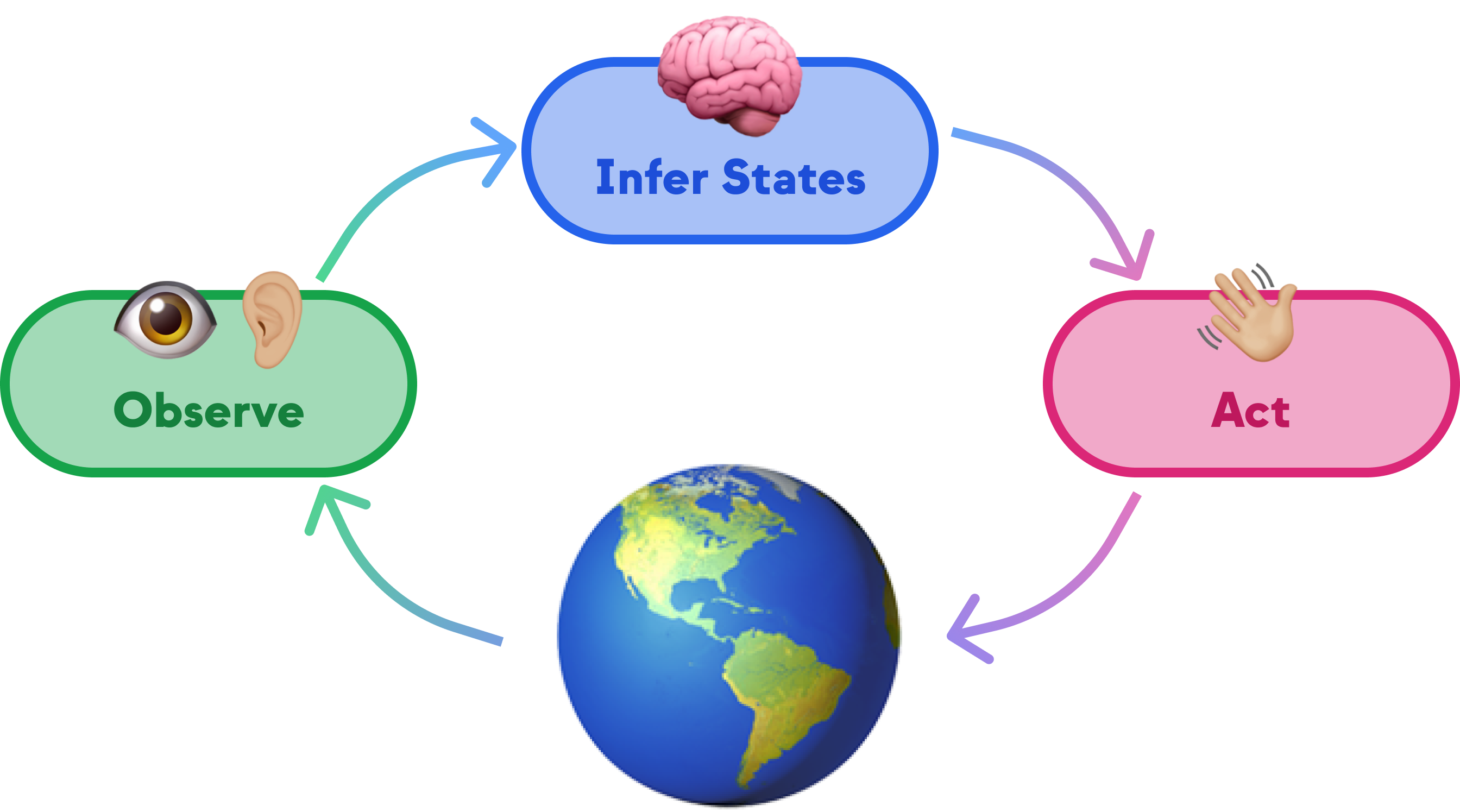
I don't want to get too deep into the math — for that I recommend checking out some of the resources I've linked — but what I did want to do is see if we can build some cool demos to see Active Inference in action. So let's get to it!
AI in Action: Living in a 1D World
Welcome to LineWorld. There's not much going on here. Just a line, and an agent. The agent can move left or right, and its goal is to get to the green circle.
Play around with LineWorld for a bit. Move the agent around. See if you can get it to the goal. It's not too hard, right? You can do it!
Instructions: Tap to move the agent around LineWorld. Use the buttons below to move the goal. Press start to watch the agent instinctively navigate!
Goal
So... how did it go? No really, I don't know how it went. Remember: the agent is stochastic! If you ran it a few times, it probably made some weird choices along the way but eventually reached the goal.
What does the agent know from the start?
- It knows that it can move LEFT, RIGHT, or STAY.
- It knows it can observe where it probably is on the line, but it can't see what spots are next to it
- It knows it probably will be next if it takes each action.
- It knows it has a strong preference for being on the goal.
That last one, a strong preference for being on the goal, is what motivates it to even move! Remember, Active Inference is all about minimizing surprise. But what surprises an agent? An agent is surprised when it's in a state it doesn't expect to be in. In this case, the agent is surprised when it's not on the goal.
Let's walk through an example.
Imagine an agent at the beginning of its journey, positioned on the left end of a linear world. Its initial task? Determine its next move from three options: MOVE LEFT, MOVE RIGHT, or STAY.
The agent assesses the surprise associated with each action. It knows that it is probably starting around position 0. From that, it can infer that staying put or moving left likely means remaining at position 0 — not a surprising outcome, but certainly not helpful for reaching its goal. Moving right, however, suggests a shift to position 1 (a new spot, but still probably not the goal). To our agent, being in a spot it hasn't been before is surprising.
In Active Inference, the agent seeks to minimize its free energy — stay close to the states it expects and prefers. But remember, it doesn't know what spots are next to it, whether or not the next spots are the goal, let alone how to get to the goal. At this point, all it can tell is that whether it moves LEFT or RIGHT, it (probably) will not be on the goal.
Without knowing its exact surroundings, it initially struggles to discern the most effective move. It makes a choice, let's say MOVE RIGHT, and transitions to position 1. Now, it re-evaluates its options with newly updated information.
Surprise comes in two forms: being in a state you don't like, or being in a state you didn't expect. The agent is most surprised when both are true at once.
When running these agents, I notice that the agent often suddenly turns around and heads back toward the start. To a viewer, this feels like a dumb move. But to the agent, it makes mathematical sense. Free energy minimization balances exploitation of known information with exploration of new possibilities. Sometimes, "going back to a familiar spot that isn't the goal" carries less surprise than "venturing into unknown territory that also isn't the goal." Just like humans, the agent can get stuck in a rut, preferring the safety of what it knows. Or it makes a breakthrough that propels it toward its goal.
Charting the Future
Our agent is making progress, but it's still not very efficient. It's just randomly moving around, hoping to get to the goal. And for how simple it is, it's pretty decent at it in our simple 1D LineWorld! But what if we made it a little smarter?
Baked into Active Inference is the concept of planning. It sounds more complicated, but it uses the same math — applied over multiple future time steps before the agent commits to a decision. Play around with the demo below. Adjust how far ahead the agent looks and see how its behavior changes.
LineWorld: With Planning
Instructions: Tap to move the agent around LineWorld. Use the buttons below to move the goal. Press start to watch the agent instinctively navigate!
1 steps ahead
Goal
How does our agent plan? The premise is simple. At each time step, instead of evaluating only the next action, the agent considers all possible action sequences for the next n steps and picks the first action from the sequence that minimizes total expected surprise.
For those CS folks out there — yes, planning is computationally expensive (it scales exponentially with lookahead depth). But it's powerful. Looking ahead even two or three steps makes the agent dramatically more effective.
Wrapping Up
So here's what we built: a tiny agent on a tiny line, equipped with nothing but a generative model and a preference for where it wants to be. No reward function, no gradient descent, no training data. Just Bayesian inference in a loop, and it figures out how to get where it wants to go. Add planning, and it gets there faster.
That's what hooked me. The same math that explains why a cell maintains homeostasis can drive a synthetic agent to navigate toward a goal. It's not a metaphor — it's the same equations. I'm still digging into how this scales to richer environments and higher-dimensional state spaces, and I'd love to explore how Active Inference agents handle situations where their generative model is wrong. If any of this grabbed you, check out the resources below.